Problems with Microsoft Azure´s networking

UPDATE, IMPORTANT
Some of the claims in this post are inaccurate. The ACKed-but-undelivered problem lies either in my router or ISP - not Azure’s fault.
Until I research this topic more and update the article, these problems still stand:
- Azure has a forced artificial limit, disconnecting session with >= 4 minutes of radio silence. There is no technical requirement for this as the IP should have 1:1 mapping to the VM.
- When a session is disconnected, all incoming packets are blackholed instead of issuing an RST packet which would correctly let the sender know of connection issue, instead of just waiting and waiting.
END OF UPDATE
TL;DR: Azure has a nasty artificial limitation that results in being unable to use long-lived TCP connections that have >= 4 minutes of radio silence at any given point.
They screwed it up so hard that when connection does timeout, they acknowledge the following TCP packets with an ok flag that makes the sender think “everything is okay - the data I sent was received succesfully”, which is 100 % unacceptable way to handle error conditions.
This caused me so much pain and loss of productive work time.
Do you:
- Understand the internals of the TCP/IP protocol?
- Understand how to debug network capture dumps?
- Understand how exactly NAT works?
- Understand the behaviour patterns of your (or your partner’s) network-based applications?
- Understand the guarantees your applications can still offer even if the underlying TCP transport is stripped of its guarantees it normally has?
- Have the ability to work around said issues, if you want to provide reliable service on Azure?
If not, you and your customers might be in for a bumpy ride if you’re using Azure. Because the above details are what I had to be proficient in, when resolving an issue that Azure threw in my face.
The problem
Part of the reason why I spent so much time tackling this issue is that it was so hard to reproduce at first, because there was no clear pattern.
When I deployed an app on Azure and accessed it directly, everything worked well.
Before going to production, while testing, I put Cloudflare in front of my loadbalancer.
I kept getting alerts from my monitoring that requests are timing out. When I opened the URL the app seemed to work fine. But it only worked for some time, then the timeout hit again. I’m getting abysmal uptime for a simple HTTP “helloworld”:

Then I noticed that my app always works when I access the loadbalancer directly, without Cloudflare. But surely Cloudflare is not to blame, because I trust their technical talent?
Hunting for the root cause
I contacted Cloudflare to discuss about the issue, but they were not able to pinpoint the cause from their part. Knowing Cloudflare does good work, I kept diagnosing the issue assuming the problem is somewhere else.
I had extensively Googled for this issue, and just as I was about to give up because of not finding anything worthwhile, I discovered a Serverfault answer that seemed like it’s my exact issue (except mine’s for inbound packets). I struck gold!
The article tells us that Azure keeps a stateful NAT table for public IPs for connections to/from the VM instance. For. No. Reason. Whatsoever, since the public IP has 1:1 relationship with the VM the: point of a (stateful) NAT is useless.
I understand that when doing NAT, the table cannot grow unbounded. Therefore it has to be cleaned up. And for cleaning
up 4 minute inactivity is a reasonable algorithm. But there is no need for a stateful connection-tracking NAT.
None of Azure’s competitors require that. Some are doing NAT (since the public IP is not visible via $ ifconfig),
but they do not use connection tracking (which would bring issues like the ones we’re discussing).
Verifying the root cause theory
Knowing where to look for, I set up netcat as a server on Azure VM by running $ nc -l -p 1234,
and connected to it from outside with $ nc <ip of said box> 1234.
Understanding the rule, timeout is at 4 min of inactivity, I tested this simple scenario:
- Send “a” on the client.
- Verify that “a” arrived on the server.
- Wait 1 minute.
- Send “b” on the client.
- Verify that “b” arrived on the server.
- Wait 4 minute and 30 seconds.
- Send “c” on the client.
- Verify that “c” did not arrive on the server.
Here’s the the end result of the screen in the client:
$ nc <ip> 1234
a
b
c
And the server:
$ nc -l -p 1234
a
b
Sure enough, c did not arrive at the server. Timeout problem confirmed.
The case of acknowledged-but-undelivered packets
While debugging for the timeout problem with tcpdump, I stumbled upon another catastrophical issue that I
found was shocking: after timeout, even though their SNAT gateway effectively dumps my packets in the trash,
their SNAT gateway acknowledges my packets by “thanks, I received your data”. Here’s the client screen:
(after “a” I waited > 4 minutes, “b” through “g” were sent at ~1 sec intervals)
$ nc <ip> 1234
a
b
c
d
e
f
g
Server:
$ nc -l -p 1234
a
And client’s TCP traffic (illustration on fundamentals),
in chronological order (-> client-to-server, <- server-to-client):
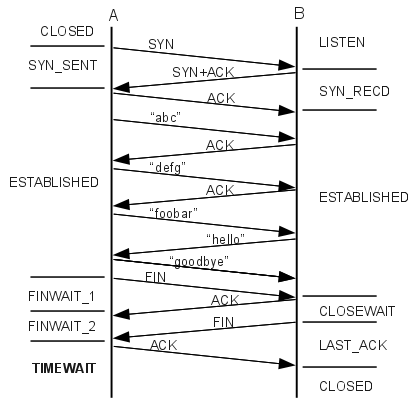{kind=link}
-> SYN
<- SYN, ACK
-> ACK
-> PSH ("a")
<- ACK
(wait > 4 minutes. the server never sees the following conversation)
-> PSH ("b")
<- ACK
(wait a bit)
-> PSH ("c")
<- ACK
(wait a bit)
-> PSH ("d")
<- ACK
(same here)
-> PSH ("e")
<- ACK
(same here)
-> PSH ("f")
<- ACK
(same here)
-> PSH ("g")
<- ACK
(19 seconds later of the first undelivered "b" message, server closes socket gracefully)
<- FIN, ACK
-> FIN, ACK
<- ACK
Why is this an issue? Think of an alert button at a bank. The alert button keeps a TCP socket open to the
alerting provider (hosted on Azure), perhaps to optimize for latency. A bank robber comes in, and an employee
hits the alert button. The alert button pushes data over the TCP stream to the alerting provider, but the
SNAT gateway has timed out the connection. However, SNAT gateway happily acknowledges the
received-but-not-ever-to-be-delivered data. The alert button thinks “all right, my job here is done :)”, FINs
the connection. Alert button signals to the employee that help is on its way, while waiting for the help which will never arrive.
Or think of a “panic button for seniors”. This issue can literally cost lives!
TCP guarantees you reliable transport for everything that was ACKed. Microsoft axed the guarantees of
TCP with Azure, risking lives. Essentially Microsoft removed the “re” from reliability and left you with liability.
There is no fix for unreliability of TCP connections on Azure.
However, there used to be a concept for this in the older Azure implementation. Why did they make things worse in the modern, newer, Azure implementation?
Recapping: what is wrong?
Essentially, I see three things wrong here:
- There is no need for a stateful NAT gateway for public IPs - but Azure forces one anyway.
- Client’s packets are acknowledged even if they aren’t going to be delivered.
- After timeout, connection is closed gracefully (
FIN), when “error, shit went south” (RST) would be more appropriate.
Why I am so pissed about this
I’ve wasted about a week in debugging this issue and when finally realizing what the root cause is is, working with a software vendor to patch around this artificial limitation.
It’s infuriating because Azure requires special support from the software for it to work properly. If there
wasn’t a useless “SNAT gateway”, errors would be appropriately handled at TCP level and packets not being ACKed
would result in re-transmit. TCP is already reliable and good at detecting errors - Microsoft broke it.
No serious cloud vendors have this issue. I tested all the solutions that are developed by grown-ups:
- Amazon AWS
- DigitalOcean
- Google Compute
=> All sockets were alive and delivering messages after 60 minutes of radio silence.
Cowardice in documentation
This article covers using the classic deployment model
Okay, what’s the link to the docs for modern Azure then? No mention ANYWHERE that there is no solution to this problem in modern Azure (except on Superuser). Unbelievable!
Microsoft screws up constantly
You’d think that when talking about cloud providers, when compute and networking is:
- lowest common denominator and
- commodity,
.. you could reasonably assume that all clouds are somewhat equal in being able to run your apps. Nope, not so fast! You can trust Microsoft to screw up once again.
Then again, why is this surprising from a vendor that thinks forcing restart of Windows 10 machines without permission at unexpected/not-well-communicated times is ok? I have lost many hours of work when Windows 10 has suddenly restarted and I have lost state of my running virtual machines because Windows shutting down does not save the states of the VMs but just discards it.
Conclusion
These issues are catastrophic in nature. If a provider is ok with:
- Forcing their customers unnecessary limitations that cause programs to not work without special patching.
- Implementing said limitation with reckless incompetency by sweeping delivery issues under the carpet.
=> Their infrastructure cannot be trusted for anything more serious than cute cat videos.
Further action
I’ve contacted Microsoft with the URL to this article asking if they’re going to do anything about this.

Thanks for reading! 😍
If you like my writing, consider following me on Twitter.
Stay updated on my blog posts & projects - sign up for
my newsletter. 🚀
No spam, unsubscribe any time.
RSS also available.